
1.5.4 字符信息的表示
由于人类的文字中存在着大量重复字符,而计算机擅长处理数字,为了减少需要保存的信息量,可以使用一个数字编码来表示每个字符。通过对每个字符规定一个唯一的数字编码,然后为该编码建立对应的输出图形,那么在文件中仅需保存字符的编码就相当于保存了文字。在需要显示时,先取得编码,通过编码表查到字符对应的图形,然后将图形显示出来,人就可以看到文字了。
1)西文的表示方法
西文字符包括拉丁字母、数字、标点符号和一些特殊符号,统称为“字符”(Character)。所有字符的集合称做“字符集”。字符集中每一个字符对应一个编码,构成编码表。
显然编码表是用二进制表示的,人们理解起来很困难。为保证人和计算机之间能进行正确的信息交换,人们编制了统一的信息交换代码。目前使用最广泛的(但并不是唯一的)西文字符集代码表是美国人制定的ASCII码表,其全称是“美国信息交换标准代码”(American Standard Code for Information Interchange)。
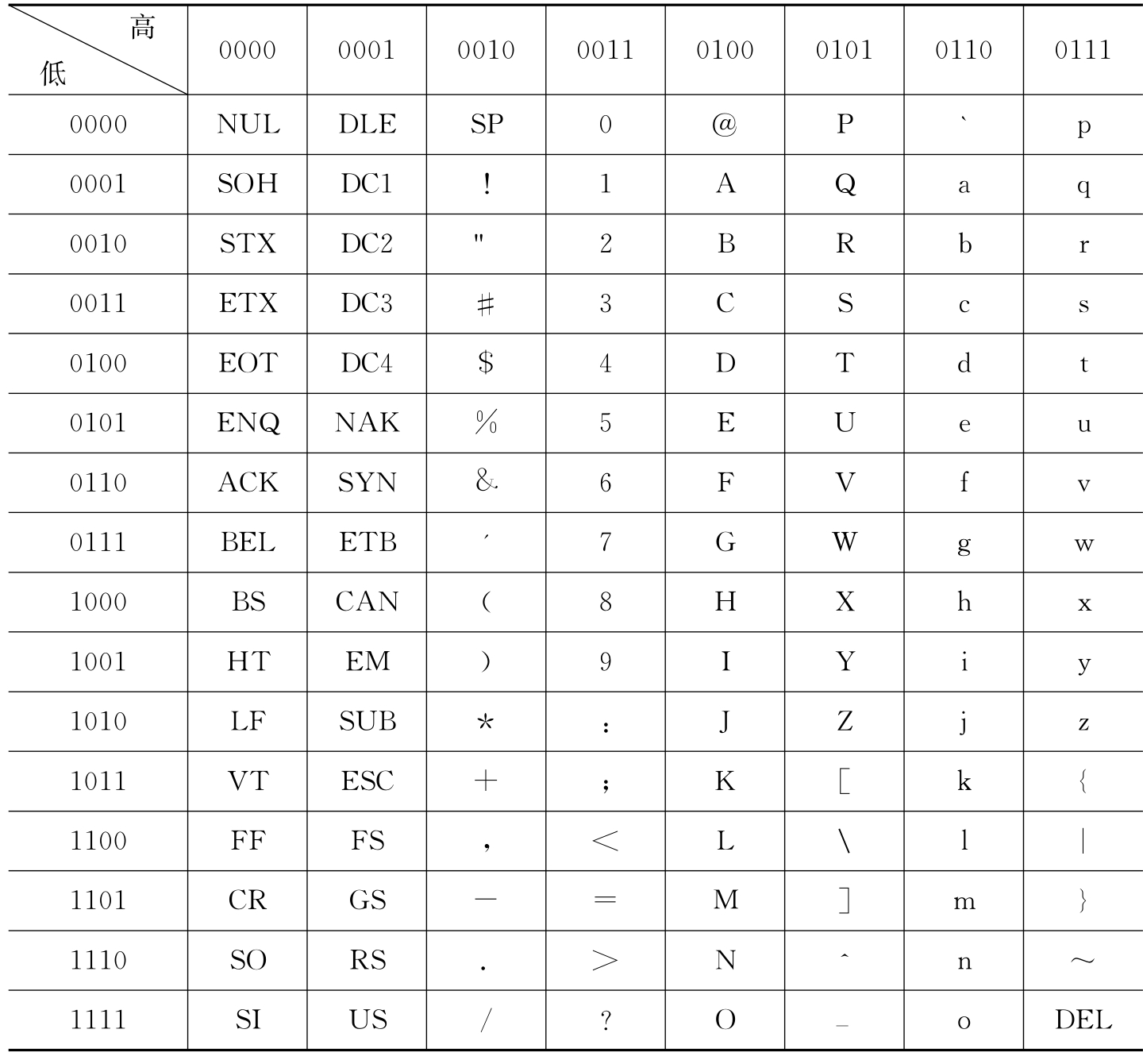
表1.3即为ASCII码表,表头中的“高”代表一个字节的高4位(b7~b4),“低”代表该字节的低4位(b3~b0)。从表中可以看出,一个字节的编码对应一个字符,最高位在计算机内部一般为“0”,故ASCII码是7位的编码,共可表示128个字符。
表中的前2列字符和最后一个字符(DEL)称为“控制字符”,在传输、打印或显示输出时起控制作用;剩下的95个字符是可打印(显示)的字符,并可在键盘上找到对应的按键。
表1.3 ASCII码表
显然美国人顺利解决了字符的问题,可是欧洲各国还没有,例如法语中就有许多英语中没有的字符,因此ASCII码不能帮助欧洲人解决编码问题。于是人们借鉴ASCII码的设计思想,创造了使用8位二进制数表示字符的扩充字符集,这样就可以使用256种数字代号来表示更多的字符。在扩充字符集中,从0到127的代码与ASCII码保持兼容,从128到255用于其他的字符和符号。由于不同语言有各自不同的字符,于是人们为此制定了大量不同的编码表,其中国际标准化组织的ISO 8859标准得到了广泛的使用。
2)汉字的表示方法
西文是线性文字,字符数量少。汉字是表意文字,属于大字符集,数量巨大,这给汉字在计算机内的表示、传输、处理及输入和输出带来了一系列的问题。
(1)汉字输入码
汉字输入码是用来完成汉字输入的汉字编码,也称为汉字的外码。汉字输入码的要求有如下特点:易学、易记、效率高、重码少、容量大等。但到目前为止,还没有一种在各方面都表现出色的编码。
一般汉字输入码可分为以下四类:①字音编码,是基于汉语拼音的编码,如智能ABC、全拼、微软拼音等,简单易学,适合非专业人员,但它的重码多,需要增加选择操作;②字形编码,是根据汉字的字形分解归类的编码,如五笔字型和表形码,这类编码重码少,输入速度快,但规则比较难,不易上手;③音形编码,吸取了字音和字形编码的优点,规则相对简单,重码相对少,但学习仍不易,这类编码有自然码等;④数字编码,使用一串数字来表示汉字,如区位码、电报码等,它们难以记忆,很少使用。
另外,汉字除了可以使用键盘输入外,还可以使用扫描仪和相应的软件进行扫描输入识别,或使用书写板进行手写汉字联机识别,甚至还可以使用麦克风通过口述的方式输入汉字。
(2)汉字机内码
虽然汉字使用不同的输入码或其他方法输入计算机,但同一个汉字在计算机内部的编码仍然是一样的。
1981年国家标准总局颁布了第一个国家标准汉字编码———《信息交换用汉字编码字符集·基本集》(GB2312)。在此标准中共收录了7 445个汉字和符号,为每个字符规定了标准代码,以便在不同计算机系统之间进行汉字信息交换。
GB2312由三部分组成。第一部分是字母、数字和各种符号共682个,统称为图形符号;第二部分是一级常用汉字,共3 755个,按照汉语拼音排序;第三部分是二级常用汉字,共3 008个,按偏旁部首排序。
GB2312的所有字符共分为94个区(即01~94行),行号称为区号;每个区再分为94个位(即01~94列),列号称为位号。某汉字所在的区号和位号共同组合成该汉字的编码,称为“区位码”。
为了与ASCII码有所区别,在计算机内部,汉字的区号和位号分别用1个字节表示,且把字节的最高位均规定为1。这种高位均为1的编码称为“机内码”,简称“内码”。
机内码与国标码、区位码有以下换算关系:
高位机内码=80H+高位国标码 高位国标码=20H+区码
低位机内码=80H+低位国标码 低位国标码=20H+位码
例如:“大”的区号是20,位号是83,则其区位码为2083(00010100 01010011),其机内码为10110100 11110011。
由于GB2312规定的字符编码实际上与ISO8859是冲突的,所以在中文环境下查阅某些西文文章,使用某些西文软件时,有时就会出现乱码,这实际上就是因为西文中使用了与汉字编码冲突的字符,被系统生硬地翻译成中文造成的。
6 763个汉字显然不能表示全部的汉字,但由于当时计算机的处理和存储能力都有限,所以在制定标准时只包含了常用汉字,因此时常会遇到生僻字或繁体字无法输入到计算机中的问题。
为了解决这些问题,在1995年我国发布了GBK,即《汉字内码扩展规范》。GBK向下与GB2312完全兼容,向上支持ISO10646国际标准(即UCS),在前者向后者过渡的过程中起到了承上启下的作用。GBK编码采用双字节表示,在GBK 1.0中共收录了21 886个符号,汉字有21 003个。
GB18030是最新的汉字编码字符集国家标准,于2000年发布并在2001年开始执行,它向下兼容GBK、GB2312标准和CJK编码(Chinese Japanese Korean,它包含了来自中国、日本、韩国的文字编码),解决了汉语、日语、韩语和中国少数民族文字组成的大字符集计算机编码问题,满足了中国、日本和韩国等东亚地区信息交换多文种、大字量、多用途、统一编码格式的要求。
由于历史原因,中国台湾、香港等地区还在使用繁体中文,他们制定了一套表示繁体中文的字符编码,称为“BIG5汉字编码标准”(简称“大五码”),采用双字节表示,但不兼容简体中文。BIG5使用了与GB2312大致相同的编码范围来表示繁体汉字。同样的编码在祖国大陆和台湾地区的编码中实际上表示的是不同的字符。当大陆的计算机遇到BIG5编码的文字时,就会转换成默认的GB2312,形成乱码。
由于历史和文化的原因,日文和韩文中也包含许多汉字,像汉字一样拥有大量的字符,他们的字符编码也同样与中文编码有冲突。《中文之星》、《南极星》等软件就是用于在这些编码中进行识别和转换的专用软件。
20世纪80年代后期互联网的出现彻底打破了人们的生活。在一切都数字化的今天,文件中的数字到底代表什么字?问题的根源在于有太多的编码表。如果全球都使用一张统一的编码表,那么每个编码就会有一个确定的含义,就不会再有乱码的问题。
于是80年代成立的Unicode协会制定了一个能够覆盖几乎任何语言的编码表,Unicode编码的全称是“通用多八位字符集”(Universal Multiple-Octet Coded Character Set,简称为“UCS”)。UCS编码空间大,但效率低。其简化方案是使用两个字节表示编码,称为“UCS-2”。
3)字符的显示(打印)
通过计算机处理后的字符如果需要在屏幕上显示或打印出来,则需要把机内码转换成人们可以阅读的字形格式。字形码又称输出码或字模,就是将字符的字形经过数字化后形成的一串二进制数,用于显示和打印字符。字形码的集合称为“字库”(font)。由于输出的需要,人们设计了不同字体的字形,也相应有不同的字库。例如英文的常见字库有“Times New Roman”、“Arial”等,汉字的常见字库有“宋体”、“楷体”、“隶书”等。一些特殊行业如广告设计、平面设计等还会使用一些特殊的字库。要显示或打印输出一个字符时,计算机根据该字符的机内码找出其在字库中的位置,再取出其字模信息作为字形在屏幕上显示或在打印机上打印输出。
点阵字形码是一种最常见的字形码,它用1位二进制码对应屏幕上的一个像素点,字形笔画所经过处的亮点用1表示,没有笔画的暗点用0表示。点阵的实例很多,例如运动场、车站码头等地的大屏幕显示屏,就是由许多行和列的灯泡组成的点阵,当某些灯亮时,就可以组成文字或图案。西文字符的点阵通常用7行5列的二进制位组成,记为7×5点阵,如图1.3所示。针式打印机的机头也是由按行、列排列的针组成的点阵,计算机控制二进制位为1的针打出去,二进制位为0的针不打,于是文字和图形就打印在纸张上了。

图1.3 7×5点阵
汉字的输出原理与西文的输出原理是相同的。不同的是汉字笔画较多,要能很好地表示1个汉字,起码需要16×16点阵才行。如果要求字形逼真美观,点阵的点数还要增加。如用24×24、32×32、48×48、64×64等,如图1.4所示,因此汉字的存储空间比西文要大很多,需要用大量的存储空间来存放字模。

图1.4 64×64点阵
注意,汉字在计算机内部都采用机内码表示,只需2个字节即可表示1个汉字。而当汉字被输出时,若使用16×16点阵的表示方法,则需要16bit×16=256bit=32Byte,即32个字节来存放1个汉字的字形码。
除了点阵字库,汉字还可以使用轮廓字库来描述。轮廓字库使用数学方程来描述字形,字形大小变化时不易失真,精度高,但技术较为复杂,例如Windows操作系统中的“TrueType”字体。
上一篇:角膜上皮层
下一篇:货币增长与通货膨胀()






