
广义最小二乘法
一、广义最小二乘法(GLS)概述
如果模型
Y=Xβ+μ(4-18)
同时出现序列相关性和异方差性,即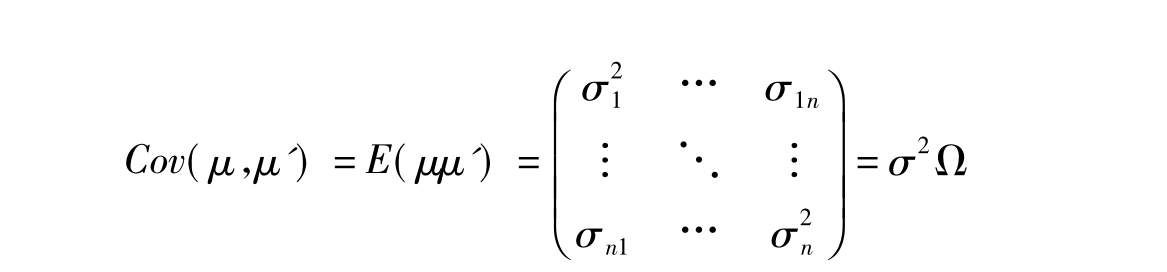
其中,Ω为一对称正定矩阵,因此,存在一可逆矩阵D,使得Ω=DD',用D-1同乘原模型(4-18)式两边,得到新模型:
D-1Y=D-1Xβ+D-1μ
即
Y*=X*β+μ* (4-19)
可以证明,模型(4-19)随机误差项μ*服从基本假设,即E[μ*(μ*)']=
σ2I。原模型(4-18)同时消除了序列相关性和异方差性。
一般来说,只要已知模型随机误差项的方差—协方差矩阵σ2Ω,就可以采用广义最小二乘法得到模型参数的最佳线性无偏估计量,特别是当模型随机误差项之间存在一阶序列相关时,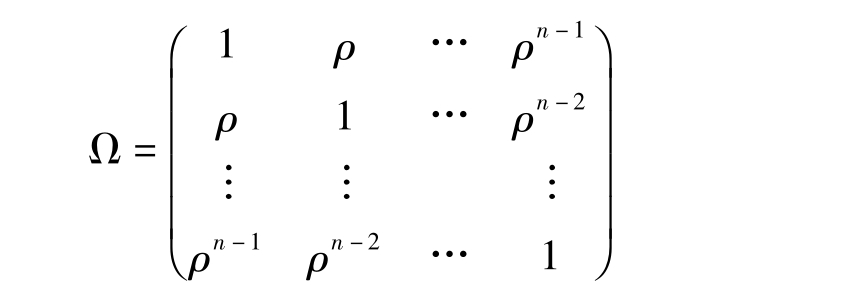 往往采用广义最小二乘法对模型进行修正。我们将以例4-2来具体说明EViews下广义最小二乘法的操作步骤。
往往采用广义最小二乘法对模型进行修正。我们将以例4-2来具体说明EViews下广义最小二乘法的操作步骤。
二、实例操作
例4-2表4-2是以1990年不变价格测算的中国人均国内生产总值(GDPP)与以居民消费价格指数缩减的人均居民消费支出(COMP),建立二者关系模型如下:
COMP=β0+β1GDPP+μ (4-20)
表4-2 中国人均居民消费与人均GDP
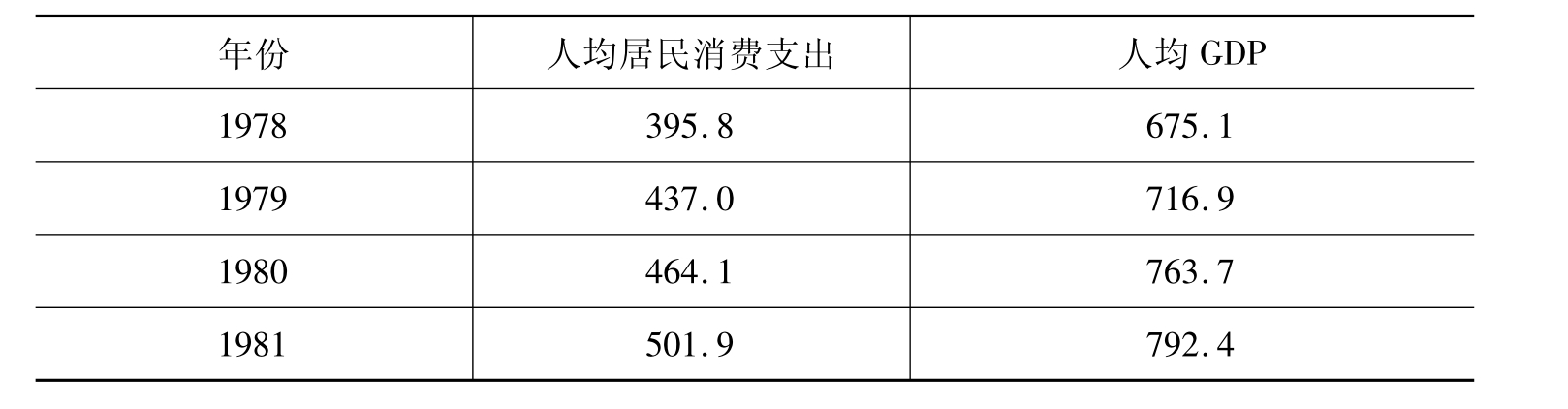
续表
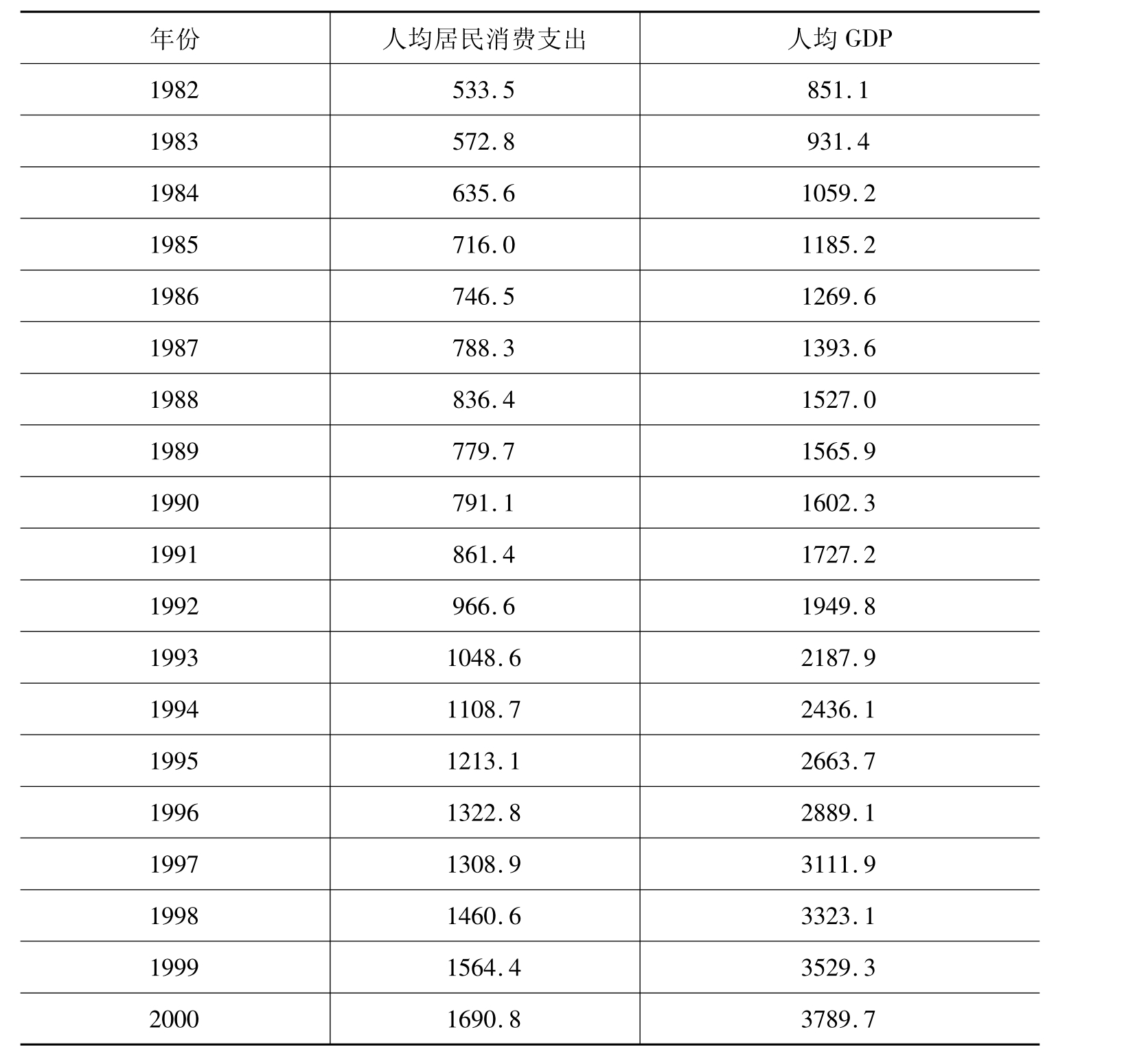
(数据来源:中国国家统计局《2001中国统计年鉴》.北京:中国统计出版社,2001.)
1.模型检验
采用普通最小二乘法估计模型,得到回归结果如图4-22所示。
根据DW值,可以判断,模型存在序列相关性。
保留估计结果残差,用残差e近似替代随机干扰项,并构造模型
et=ρet-1+εt (4-21)
以及模型
et=ρ1et-1+ρ2et-2+μt (4-22)
用以判断模型随机误差项服从几阶序列相关性。
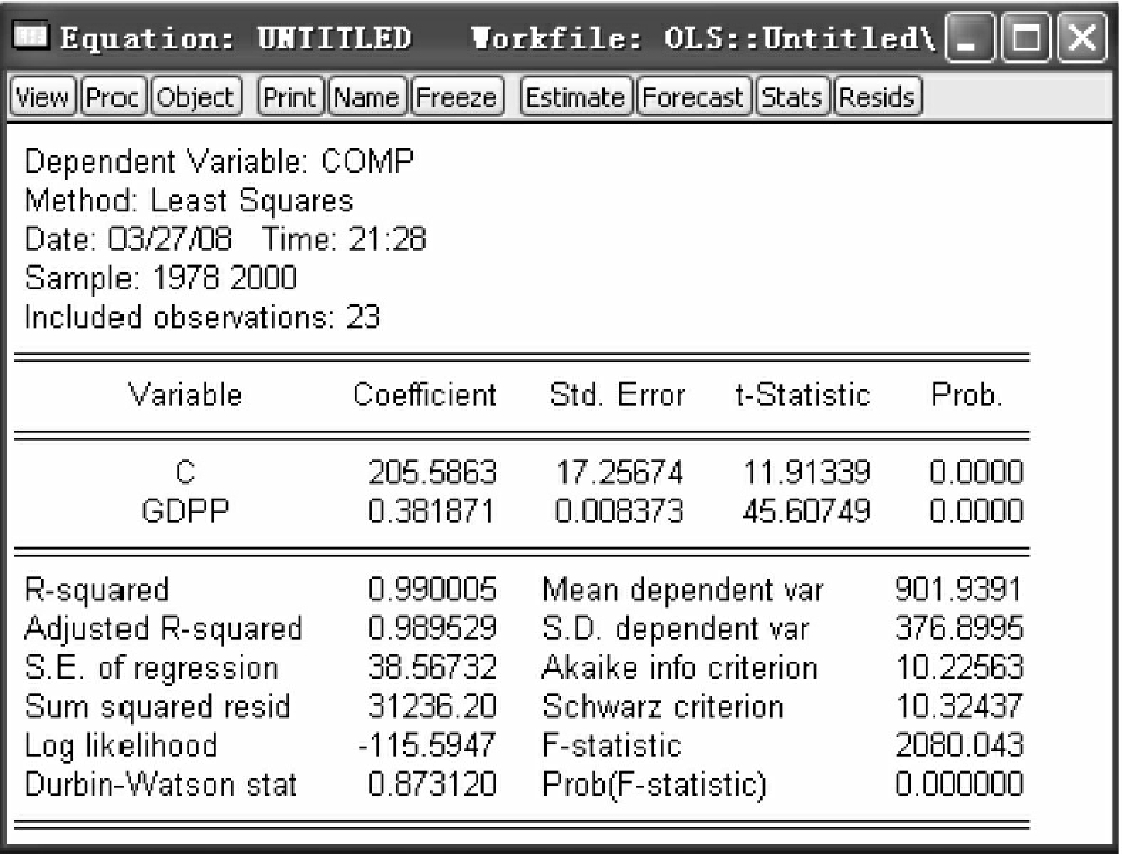
图4-22
分别对式(4-21)和式(4-22)进行最小二乘估计,得到估计结果,如图4-23和图4-24所示。
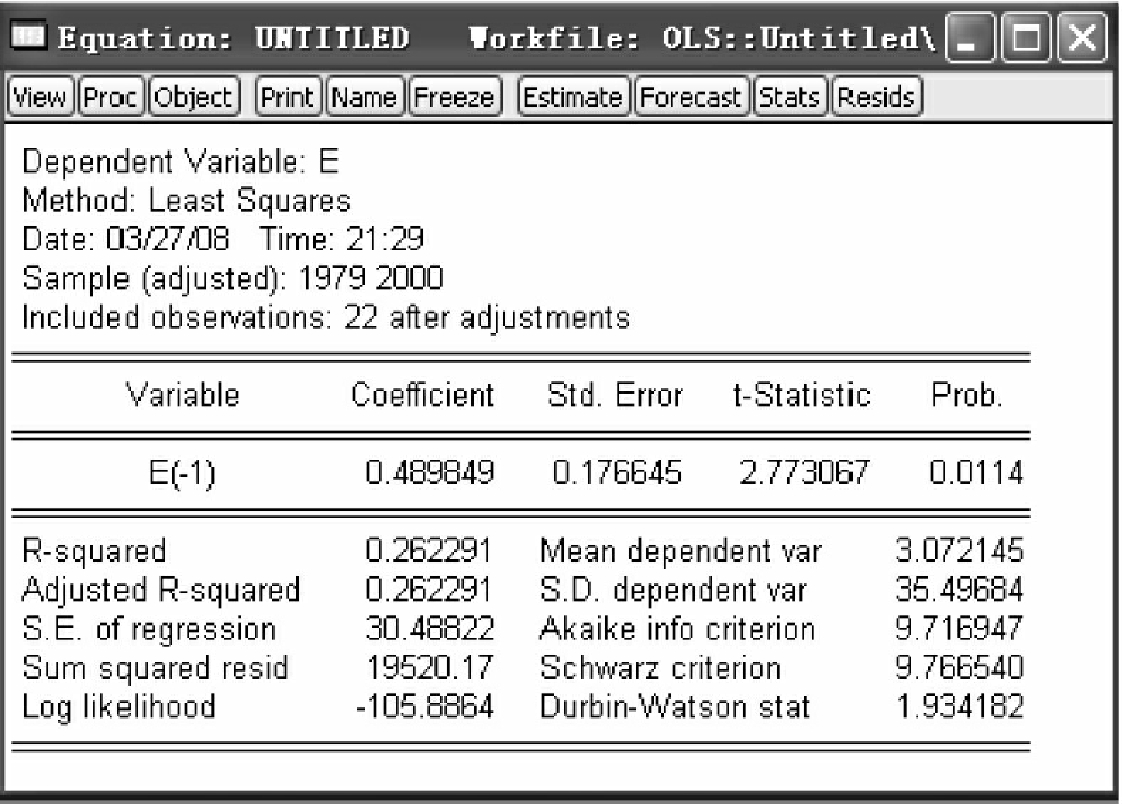
图4-23
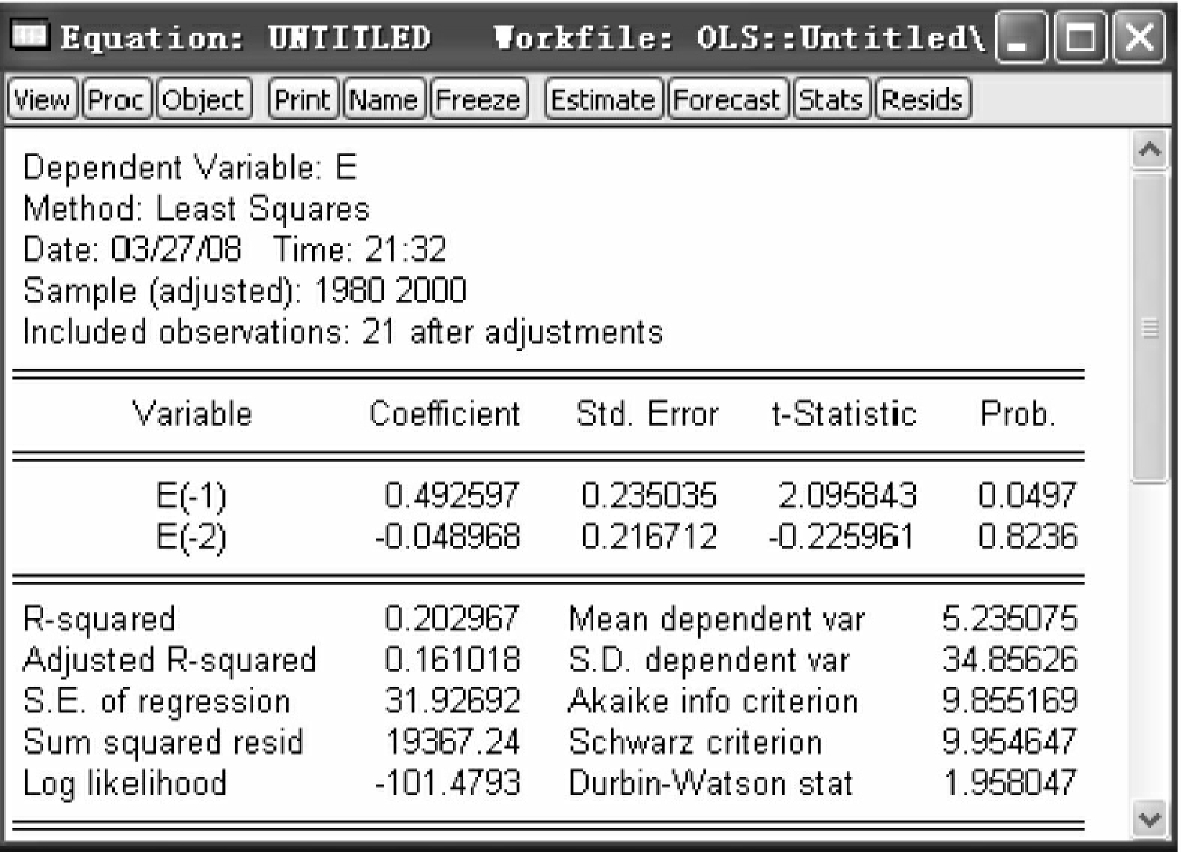
图4-24
从图4-24的回归结果可以看出,模型(4-22)中et-2的系数是显著为0的,即et-2对et没有显著影响;而et-1前系数是显著异于0的,因此,可以判断,模型具有一阶序列相关性。
2.广义最小二乘法
运用广义最小二乘法对模型进行修正,首先需要计算一阶自相关系数ρ,从而得到矩阵Ω。由于DW=2(1-ρ),因此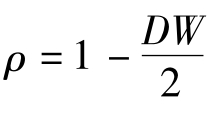 ,可以直接根据图4-22中的DW值计算ρ。此时,ρ=0.5634。
,可以直接根据图4-22中的DW值计算ρ。此时,ρ=0.5634。
(1)建立Ω矩阵
在构建Ω矩阵前,需要在EViews下建立一个空白矩阵,此矩阵的行数与列数与模型样本数相同,均为n。在该例中,样本数为23,因此先构造一个23行23列的矩阵,再根据Ω矩阵的定义形成Ω矩阵。在EViews下,可以通过菜单方式与命令两种方式建立空白矩阵。
①菜单方式:在EViews主菜单下点击Object/New Object,选定Matrix-Vector-Coef,如图4-25所示。
点击OK,弹出New Matrix对话框,在Type下选定Matrix,在右边Dimension内输入矩阵的行数和列数,如图4-26所示。
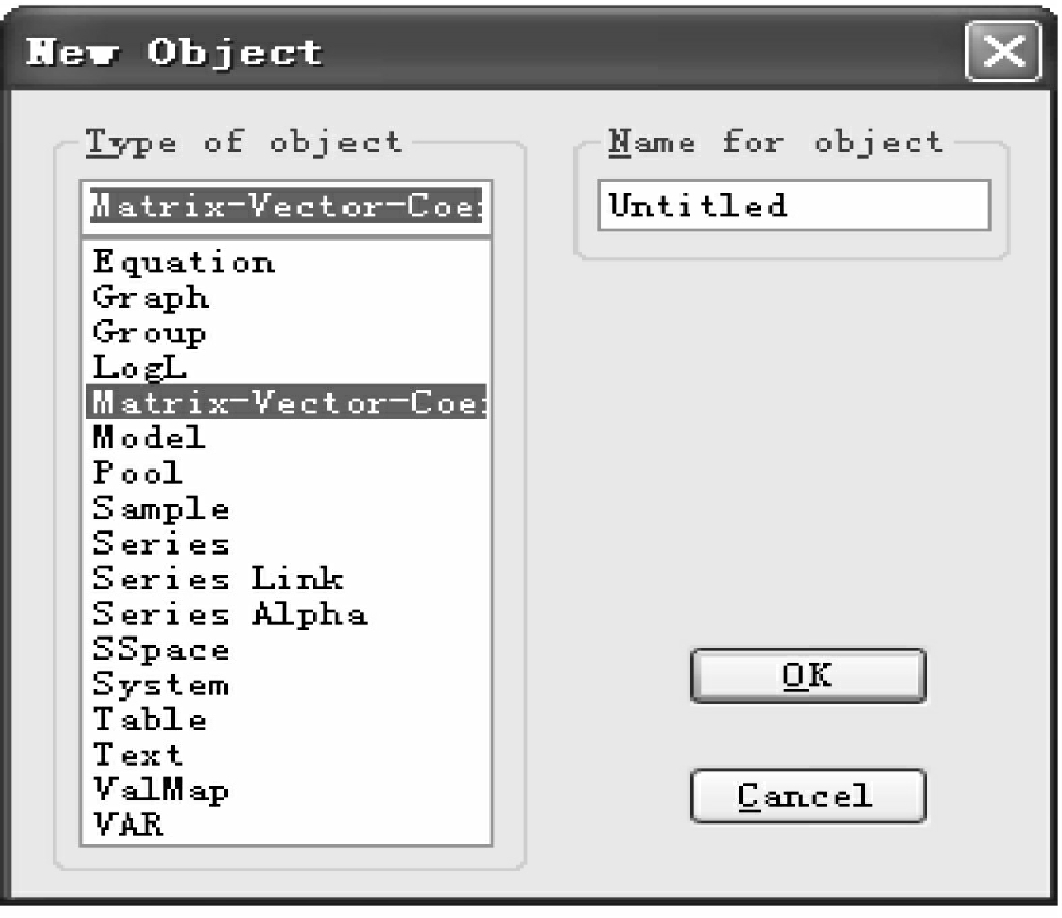
图4-25
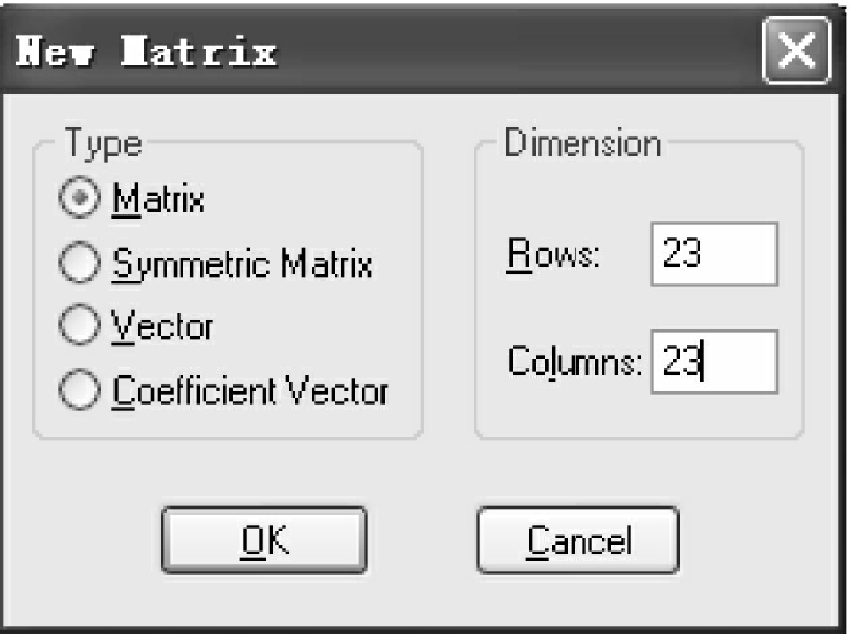
图4-26
由于Ω矩阵为一对称矩阵,因此,也可以选择图4-26中的Symmetric Matrix,从而生成对称矩阵。选定后点击OK,便得到一新的矩阵,如图4-27所示。
②命令方式:在EViews下同样可以用命令来生成矩阵。在命令框内输入如下命令:
图4-27
Matrix(23,23)fact或者Sym(23)fact
就可以得到一个23行23列的空白矩阵。其中,matrix为建立矩阵的命令,括号内分别表示矩阵的行数和列数,fact是对矩阵的命名,也可以选择其他名称。Sym表示建立对称矩阵,括号内是矩阵的维数。命令结果与图4-27相同,根据Ω的定义对矩阵进行编辑,由前所知,求得一阶自相关系数ρ=0.5634,而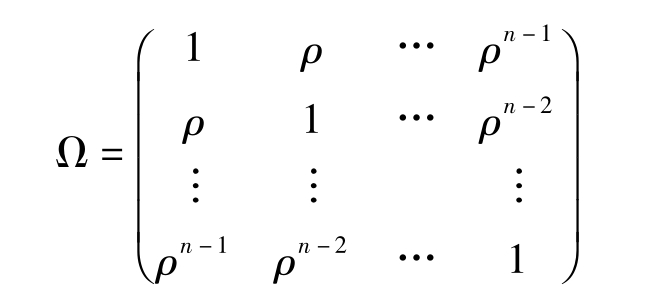
因此,第一行与第一列分别输入1,ρ,ρ2,…,ρ22,将ρ=0.5634,即在空白矩阵内输入1,0.5634,0.3174,…,3.30E-06,Ω为一对称矩阵,按照同样的方法为矩阵赋值,得到Ω矩阵(见图4-28)。
(2)分解Ω矩阵
将Ω矩阵进行Cholesky分解,从而得到可逆矩阵D,分解命令为:
Matrix fact1=@cholesky(fact)
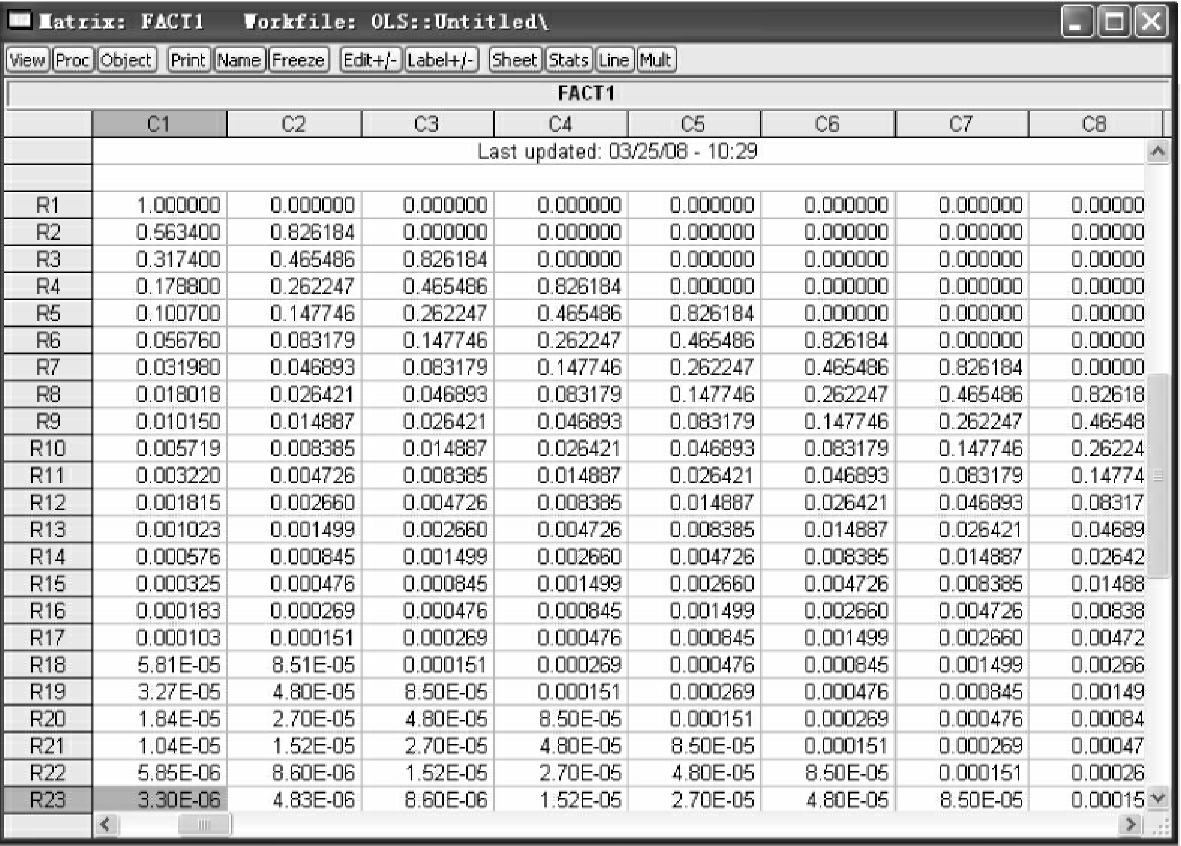
图4-28
其中,fact1表示分解后的矩阵D,@表示进行函数运算,cholesky(·)表示分解矩阵,得到矩阵D(见图4-29)。
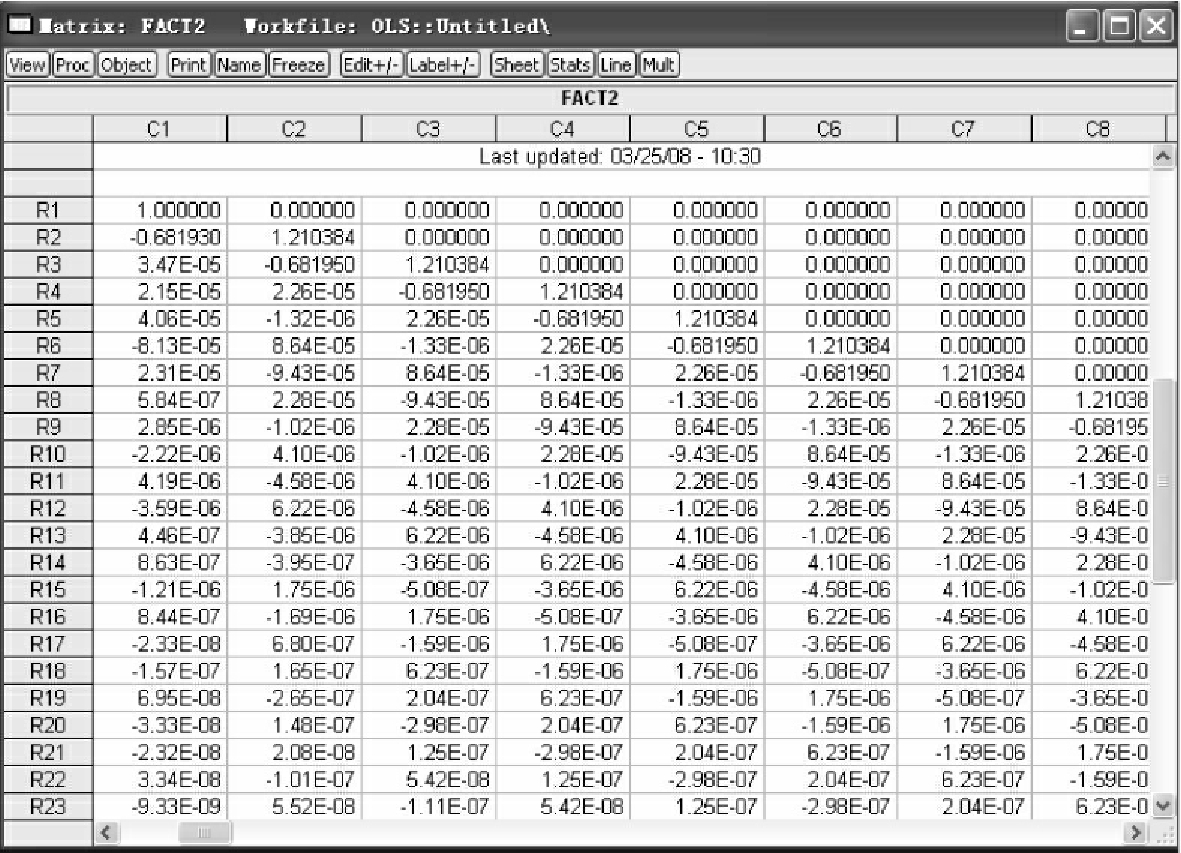
图4-29
(3)求D逆矩阵
得到分解矩阵D后,便需要求出D的逆矩阵D-1,求逆矩阵命令为:
Matrix fact2=@inverse(fact1)
其中,fact2代表D-1,inverse(·)表示求逆矩阵,得到D-1,如图4-30所示。
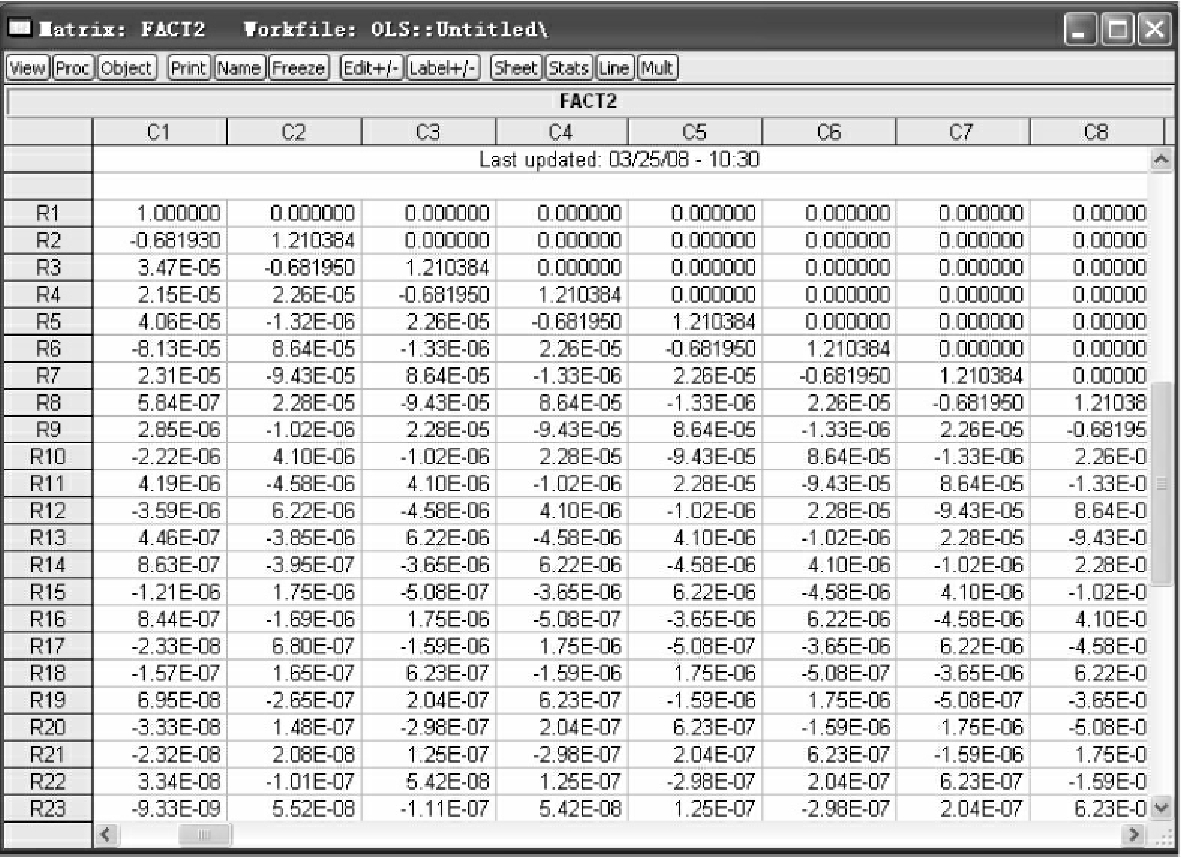
图4-30
用D-1同乘原模型(4-20)式两边,便可以得到消除序列相关的新模型。因此,对原数据进行变化,以得到新序列D-1COMP与D-1GDPP,通过命令方式建立新序列:
Matrix COMP1=fact2*COMP
Matrix GDPP1=fact2*GDPP
其中,COMP1与GDPP1为对新序列的命名,fact2*GDPP表示两矩阵相乘,在此命令下建立的是原序列的矩阵形式,不能直接进行最小二乘估计,需要将序列数据转化到序列中,通过命令
data COMP2GDPP2
得到两新序列窗口,在空白序列中录入COMP1与GDPP1的值,便得到其序列形式,如图4-31所示。
(4)估计新模型
数据经过转化后,原模型(4-20)变为COMP2=β0+β1GDPP2+εt(4-23)
其中,εt为满足基本假设的随机干扰项。在命令栏内输入
ls comp2 c gdpp2
结果如图4-31所示。
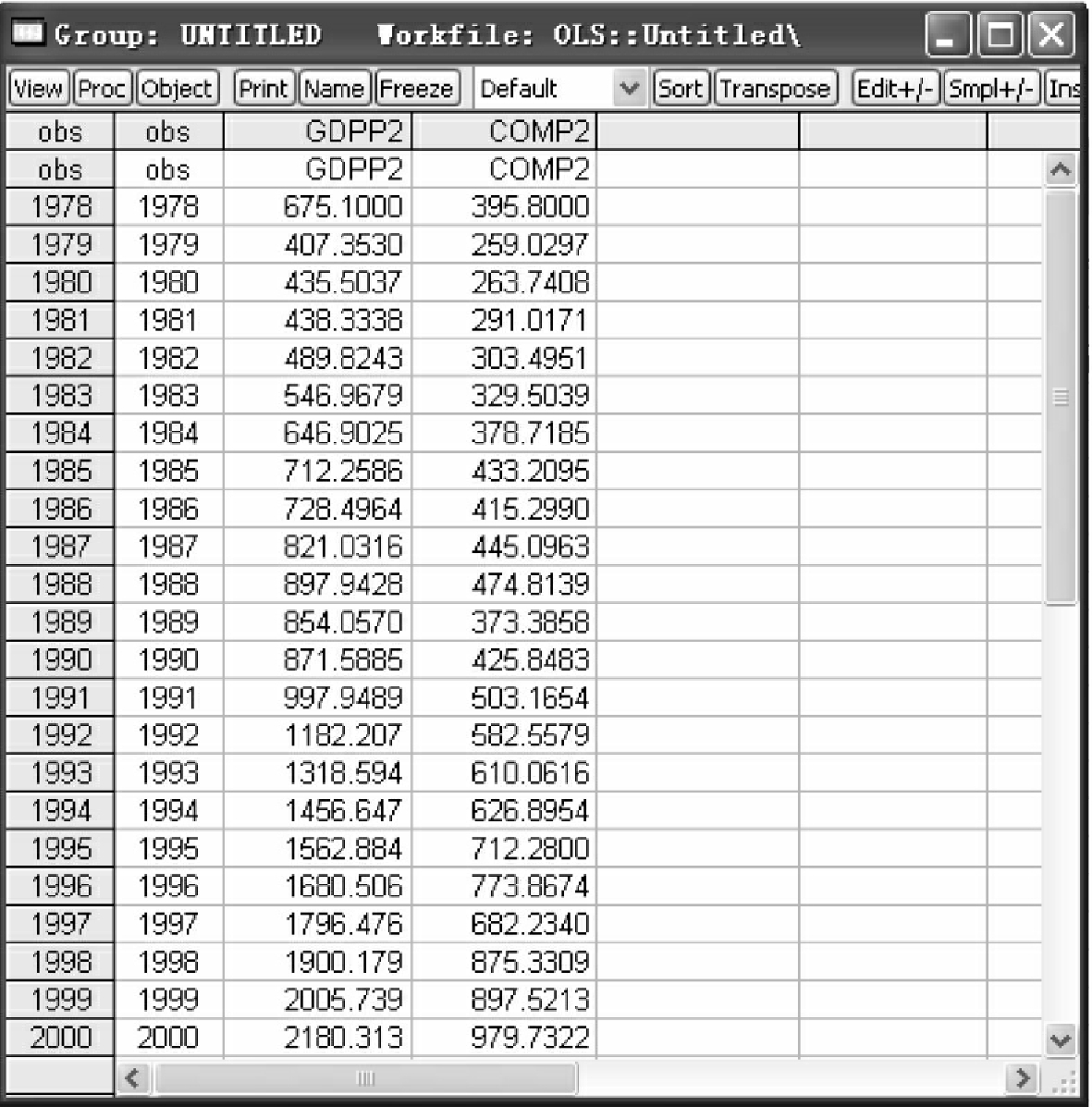
图4-31
对新模型(4-23)进行普通最小二乘估计,估计结果如图4-32所示。
分析图4-32中估计结果:t统计量显示解释变量估计系数均显著异于0,对被解释变量存在显著影响;F统计值表明模型整体显著;此时,DW值为2.115,围绕在2附近,说明模型的序列相关性完全得以消除,估计出的参数为最佳线性无偏估计量。
值得注意的是,由于广义最小二乘法既能消除序列相关性,又能消除异方差性,因此,当我们拿到数据时,无论它是否存在异方差性或者序列相关性,我们均可以直接运用GLS方法进行估计。在存在异方差性或者序列相关性时,即可消除;如果不存在,其相对于普通最小二乘法,不会影响估计结果。
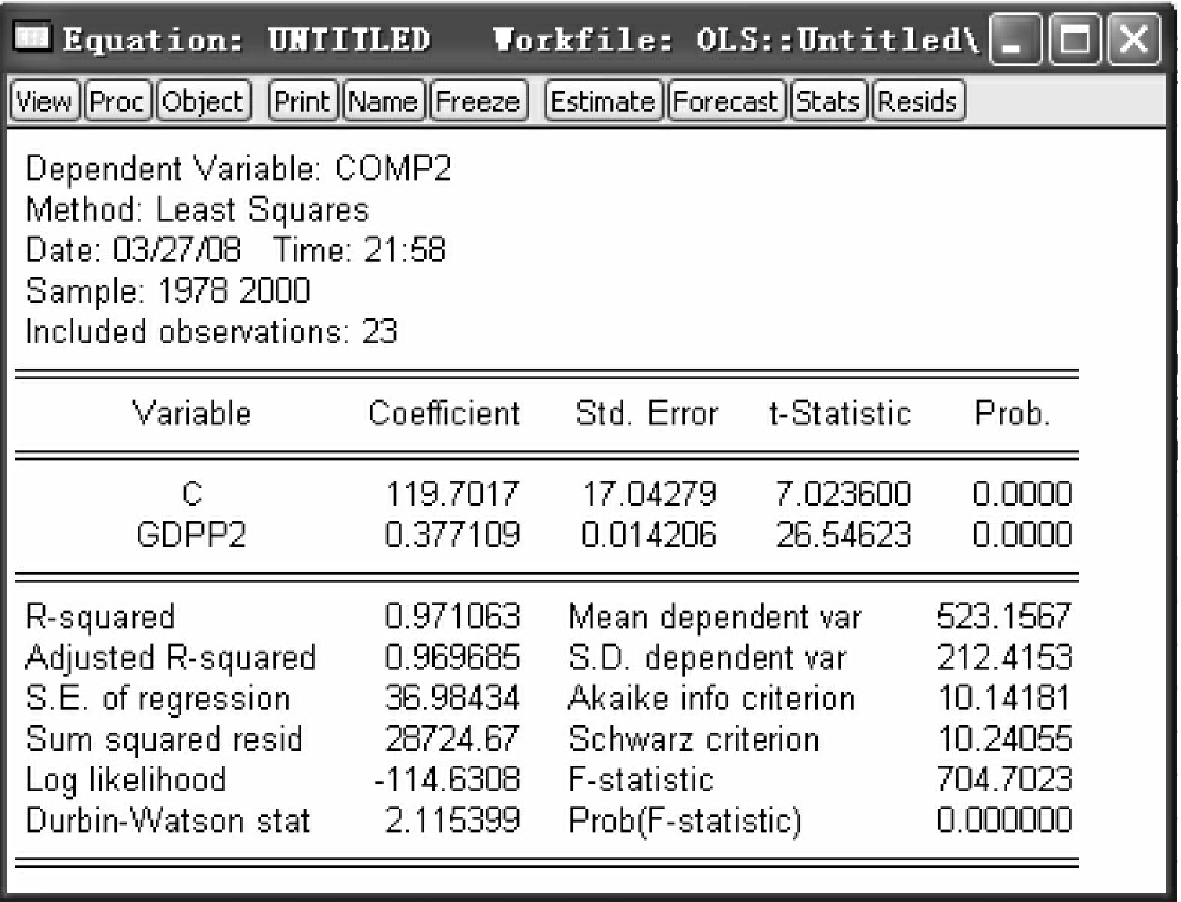
图4-32
3.结果分析
根据广义最小二乘法估计结果,可以写出人均居民消费估计方程
COMP^=119.7+0.382GDPP (4-24)
方程表明,人均GDP每提高1个单位,将使人均居民消费增加0.382个单位,因此,加速中国经济发展,提高GDP,将带来中国居民消费的改善,提高群众福利。
上一篇:脂肪变性引起细胞坏死的机制
下一篇:商标翻译的方法






